


Breaking through a machine learning interview can seem like a challenging task. You should know this: it goes beyond only your resume’s degrees or qualifications. When navigating through machine learning common interview questions, you’ll often be in a technical, open-ended conversation. However, it’s one approach that catches the interviewer’s attention. After all, taking a decisive approach to practical machine learning challenges is what stands out in the market.
So what, therefore, ought one to expect? Let’s note some of the most often asked machine learning interview questions, along with terminologies, methodologies, and algorithms related explicitly to machine learning engineer interview questions—so that you might better prepare. This article will lead you through many machine learning engineer interview questions and offer tools such as machine learning interview questions to help you ace the interviews with flying colors.
1. What do you understand by machine learning?
Machine learning, is an important aspect of artificial intelligence, enables the machines or computers to learn or improve their performance from provided data they trained without any explicit programs. Machine learning is quickly growing into one of the most sought-after careers today. As technology is evolving per day, the field is moving towards building systems that can learn from data, recognize patterns, and make decisions with minimal help from humans. The goal is to have systems that can adapt and improve on their own, making them more efficient over time. The machine learning models are skilled in data to increase performance over time progressively.
2. How is Machine Learning different from traditional programming?
Machine learning (ML) takes a completely different path compared to traditional programming when it comes to solving problems. In traditional programming, developers write explicit algorithms and steps for a program to follow. They create fixed rules to compile the programme and get the desired outputs.
But machine learning is completely different from traditional programming, ML algorithms train on a large data model. The model identifies the patterns in large data sets, makes predictions or decisions based on provided input. This data-driven approach allows machine learning models to learn from new information and improve their performance over time. Traditional programming lacks these characteristics because it runs on static rules and predefined logic.
3. How does machine learning work?
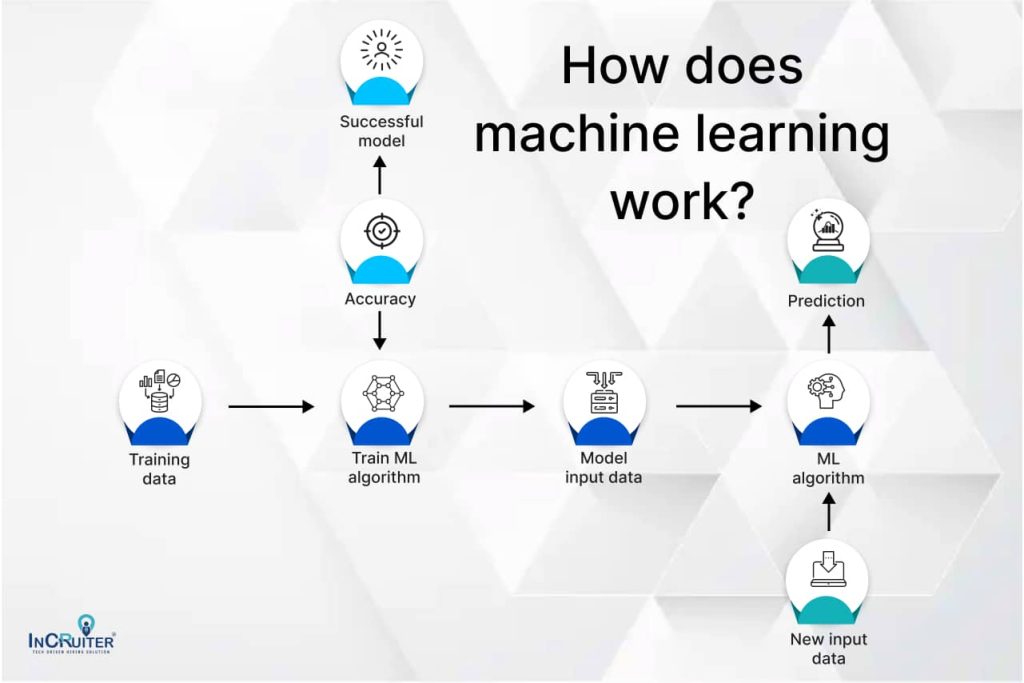
The machine learning algorithms are shaped on a training dataset to form a model. The trained Machine learning algorithm uses the created model to generate a prediction as fresh data is fed. Moreover, the forecast is tested for correctness. The ML algorithm is repeatedly used or trained depending on its accuracy using an updated training set until the required accuracy is attained.
4. What are some common applications of machine learning in real-world industries?
Machine learning has widely been used across various industries, transforming the way businesses work and make necessary decisions. Some common applications include:
- Healthcare: ML algorithms are transforming healthcare industry by their predictive analytic capabilities. This helps the doctors predict patient outcomes through the data patterns, identify diseases, prescribe personalized medicines to each patient.
- Finance: In the finance sector, machine learning is a key tool to fraud detection. Banks use this to assess the credit score and analyzing the loan approval decisions. It also use in algorithmic trading and in managing risks by predicting patterns in customer behavior.
- Retail: Retailers use ML to improve the customer experience and also help in recommendation systems by identifying user choices and behaviors.
- Transportation: Autonomous vehicles means self driving cars primarily relying on ML for navigation, avoiding obstacles, and to find the best routes. Logistics companies use this in demand prediction and optimizing the delivery routes.
- Manufacturing: In manufacturing ML helps in prevention of equipment failures. By predicting when the machine might fail ML helps in fixing the issues before they cause delays.
Also read: How AI Interviews Are Shaping Recruitment in the BFSI Industry?
5. What are the types of machine learning?
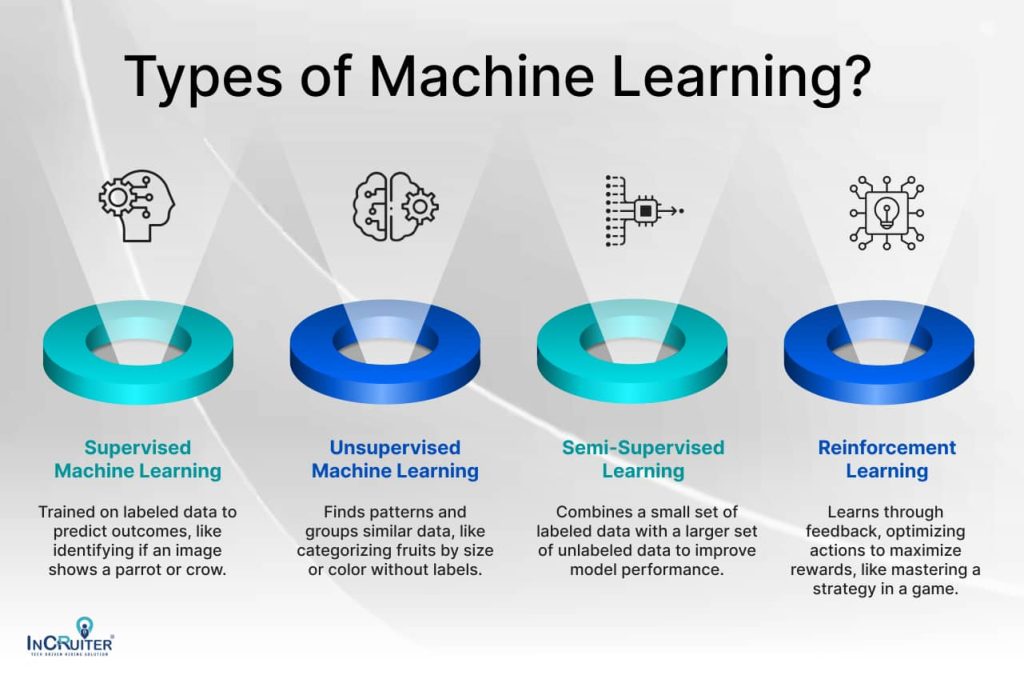
Supervised machine learning
This model is trained using labeled data in supervised learning—where the correct output is already known. From this information, the machine develops predictions on fresh, unknown data. For instance, determining if an image depicts a parrot or crow depends on color and shape.
Unsupervised machine learning
Unsupervised learning excludes labeled data. Instead, the machine discovers trends and associations inside the data, including grouping related fruits depending on size or color.
Semi-supervised learning
Combining both techniques, semi-supervised learning uses a small amount of labeled data alongside a greater volume of unlabelled data to enhance the model’s performance when labeled data is limited.
Reinforcement learning
Enhancement Learning is learning by feedback. Like a game in which it learns the optimum strategy to maximize points, the machine interacts with its surroundings, getting rewards or penalties for its activities.
6. How can you describe the variations between supervised and unsupervised learning?
Supervised learning uses labeled data to learn from instances, while unsupervised learning searches the data to identify trends free from labels. Supervision is about learning under direction. Say you have a data set, and every bit of information has a label or accurate response. The machine learns prediction skills using these labeled instances.
If you wish a model to discriminate between emails that are spam and those that are not, for example, you would offer examples of both, tagged as “spam” or “not spam.” The model then picks on the trends connected to every label.
On the other hand, unsupervised learning is about proficiency in handling unstructured data-seeking trends without needing prior classifications. The model is not given specific instructions on what to look for but is presented with data and left to its own devices. For example, with a large set of consumer data, an unsupervised machine learning model could autonomously group consumers with similar purchasing patterns, even without explicit instructions on what those groupings should be.
7. How do you describe a confusion matrix?
The confusion matrix makes one understand how to assess the performance of a model. It evaluates the depth of performance of a classifier and clarifies several results of the prediction and results of a classification problem using a table arrangement.
A confusion matrix represents every real and predicted value of a classifier through the meticulous table. This gives a clear view of how well the model is performing. This tool plays a critical role in checking the performance of classification model, which include True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN).
8. How Do You Address Missing Information?
Usually, starting from the degree and reason for the missing data, a data scientist addresses missing information in a dataset. Eliminating rows or columns with missing data is a frequent approach, mainly if the dataset is large enough to preserve its integrity upon removal or if the total amount of missing information is minor.
Imputation, an essential strategy for managing missing data, involves replacing missing values with substitute ones. For numerical data, this could include using the mean, median, or a prediction derived from other accessible data. The most often occurring category or a placeholder could be used for categorical data. This process is crucial for maintaining the integrity of the dataset and ensuring accurate analysis and modeling.
Sometimes, it’s crucial to look at whether the missing data follows a trend since this might throw more light on the dataset. The particular context and the possible influence of the missing data on the general analysis or model will determine the method selected.
9. How can you explain overfitting and underfitting in Machine learning?
Overfitting is described when a model that learns the training data too well—capturing noise and details that may not generalize to new data may suffer from unknown data. It is as if one is learning solutions rather than the ideas.
Conversely, underfitting results from a too-basic model fail to capture the data’s underlying trends, compromising training and fresh data performance. It’s like needing to read more and pass over crucial information. However, by understanding the role of complexity and how to balance it, you can effectively avoid both overfitting and underfitting, giving you control over your model’s performance.
However, along with these basic ideas on some of the most commonly asked questions, you can also explore how AI interviews are changing the game for tech recruitment to get a good knowledge about it all.
10. What is Stemming and Lemmatization?
Essential natural language processing methods that reduce words to their underlying forms are stemming and lemmatization. These role-specific machine-learning techniques minimize the structural variation of words in a sentence.
Stemming is utilized in producing abbreviated words. It eliminates affixes to generate the base form (e.g., “Changing” becomes “Chang”). Search engines extensively apply this method—which stores just word stems—for storage optimization.
Lemmatization, a method that ensures accuracy by turning words into their root forms (e.g., “Changing” becomes “Change”), guarantees the outcome is a legitimate, meaningful term. Both techniques standardize text, but lemmatization’s accuracy and significant base words offer improved analysis, instilling confidence in its results.
Incorporating such trivial changes in your preparation can significantly impact recruiting success. Read more about hiring here: Choose InCruiter- Get A Competitive Edge In Hiring Of Tech Talent
11. What is Syntactic Analysis?
Syntactic analysis, sometimes referred to as syntax analysis or parsing is one of the third phases of natural language processing and text study, which reveals the logical meaning of a sentence or part of the sentence. It emphasizes the link between words and sentence grammatical construction. One may also argue that applying grammatical rules helps one to process the natural language. It might be characterized as the programming tool for input data (text) providing structural representation of the input following formal grammar’s accurate syntax check.
12. Explain the difference between supervised, unsupervised, and reinforcement learning.
Machine learning is divided into three main parts: supervised learning, unsupervised learning, and reinforcement learning, each serving different purposes based on the data available.
| Aspect | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
| Data | Labeled data (input-output pairs) | Unlabeled data (only input) | Interacts with environment, no explicit input-output data |
| Objective | Learn mapping from input to output | Find hidden patterns or structures | Learn optimal actions through rewards and penalties |
| Common Tasks | Classification, Regression | Clustering, Association | Decision making, Game playing, Robotics |
| Training Process | Learns from labeled examples | Identifies patterns in unlabeled data | Learns from feedback (rewards/penalties) |
| Output | Predicts known outputs for new inputs | Groups or structures data based on similarities | Optimal actions for maximizing cumulative rewards |
| Example Application | Predicting house prices based on features | Customer segmentation for marketing | Teaching a robot to navigate a maze |
| Learning Type | Direct feedback provided | No direct feedback | Feedback through interaction with the environment |
| Key Concept | Correct predictions based on labeled data | Discovering unknown patterns | Learning through trial and error |
13. What is the bias-variance tradeoff in machine learning?
Bias occurs when the ML model simplifies a complex real-world problem too much by neglecting important patterns in the data. When these errors occur the model underfits, meaning it is not learning from the data.
On the other hand variance is about how sensitive a model is to change in the training data. When variance is on high side it indicates model overfitting that picks up on random noise instead of the real patterns of data.
The tricky part is when you try to reduce the variance the bias goes up, and vice versa. The well-balanced model tries to keep both bias and variance low by utilizing the various techniques like cross-validation, combining multiple models and adding controls to the model which helps manage this balance. This is how the ML model can work better with fresh unseen data.
14. What are the key differences between classification and regression?
Classification and regression are two primary types of supervised learning tasks, each serving different purposes based on the nature of the output variable.
| Aspect | Classification | Regression |
| Purpose | Classification is used when we need to group data into categories. | Regression is used when we want to predict a continuous numerical value. |
| Output Type | The result is a label or category (like “spam” or “not spam”). | The result is a continuous value, like a price or temperature. |
| Example | Sorting emails into “spam” and “not spam”. | Predicting the price of a house based on its size and location. |
| Common Algorithms | Decision Trees, Logistic Regression, Support Vector Machines | Linear Regression, Polynomial Regression, Regression Trees |
| Use Case | Best for problems where you want to sort or label data into specific groups. | Best for problems where you’re trying to predict a value or quantity. |
15. What is cross-validation, and why is it important?
Cross-validation a statistical technique used to the performance of machine learning models. It involves the training data into smaller segments. Then, an ML model is trained on some segments while being tested on others. This process checks how well the model can handle, unseen data.
One popular method of cross-validation is called k-fold cross-validation. In this approach, the splits into k sections or “folds.” The model undergoes training k times, utilizing k-1 folds for training and reserving one fold for testing each time. This method offers insights into the model’s effectiveness and helps minimize the risk of results leaning too heavily on any single data split.
Cross-validation plays a vital role in machine learning. It helps prevent overfitting, a situation where a model becomes overly specialized with its training data but fails to perform accurately in other contexts. Additionally, it provides insights into how a model behaves across different datasets and predicts its potential performance in real-world applications. By adopting this approach, practitioners can refine their models, ensuring better reliability and performance over time.
16. Describe what a decision tree is and how it works.
A decision tree is a method used in supervised learning, often applied in both classification and regression tasks. It works like a map of decisions, where each point on the tree involves a test on a certain attribute or feature, and each branch of tree shows the possible outcomes of test. At the ends of the branches, called leaf nodes, you’ll find either a label (for classification) or a continuous value (for regression).
Building a decision tree means taking a dataset and splitting it repeatedly. The goal is to keep dividing the data based on the feature that gives the most useful information. In decision trees, splits are often made to reduce something called ‘Gini impurity,’ which measures the impurity or impurity of a node. The process keeps going until the tree hits a certain limit, like reaching a set depth or having too few data points left to split further.
Decision trees are popular because they are easy to understand. They work well with both numerical and categorical data , without needing much data preprocessing beforehand. However, one of the biggest challenges is that they can become too complex, leading to overfitting—where the model becomes too tailored to the data it was trained on and struggles to handle new data. To address this, people often trim the tree (known as pruning), limit how deep it can grow, or use advanced methods like Random Forest to combine multiple trees for better results. In short, decision trees are simple but powerful tools, and with the right techniques, they can be even more effective.
17. What is a Random Forest, and how does it differ from a decision tree?
A Random Forest is a method in machine learning where many decision trees are combined to make a prediction. For classification tasks, it picks the most common answer from the trees. For regression, it averages their predictions.
But how is it different from a decision tree? Let’s break it down:
| Aspect | Decision Tree | Random Forest |
| Concept | A single map that learns from training data but may struggle with new data. | Combines many trees to make better predictions and works better on new data. |
| How They’re Built | Looks at the entire dataset and follows a single path, which can miss patterns. | Builds each tree using a random part of the data, giving the forest a broader view. |
| Choosing Features | Considers all features when making decisions, leading to less variety. | Selects features randomly at each split, creating more variety and better results. |
| Performance in Real Life | May perform worse with complex data and new situations. | Performs better overall and can show which features are most important for predictions. |
18. How do gradient descent and stochastic gradient descent (SGD) work?
The gradient descent is the method that helps machine learning in their betterment by lowering down the error in their numbers of predictions. It simply involves adjusting the model settings, step by step, in the direction that reduces the number of errors. The size of the steps depend on the learning rate.
Stochastic Gradient Descent (SGD) is a version of gradient descent that works faster by updating the model parameters using just one example of data at a time, rather than full datasets. While optimization creates some randomness and noise, it can make the model for quick updates and can help escape local minima.
Here’s how they differ:
- Data usage: Gradient descent checks all the data before updating the model, while SGD uses just one data point at a time. This makes SGD noisier but quicker.
- Speed: SGD updates the model faster, especially with big datasets, because it keeps learning from smaller pieces of data more frequently.
- Movement: SGD might oscillate around because of the noise, but this bouncing can sometimes help find even better solutions by exploring different paths.
19. Explain what feature selection and feature engineering are.
Feature selection and feature engineering are two important parts of machine learning, and they both impact model performance.
- Feature Selection is about selection of most relevant pieces of features from the original dataset. The idea helps the model learn faster and improve accuracy by removing the extra information that doesn’t add much value. This makes the model simpler and quicker. There are several techniques to do feature selection, like filter methods (e.g., correlation coefficients), wrapper methods (e.g., recursive feature elimination), and embedded methods (e.g., LASSO).
- Feature Engineering, on the other hand, is something that improves the model performance by making new features from existing data. It transforms raw data into meaningful inputs that make it easier for the model to understand. This includes techniques like normalization, encoding categorical variables, creating interaction terms, and aggregating features.
20. What are the differences between L1 and L2 regularization?
L1 and L2 regularization avoids overfitting in ML models by penalizing the condition of loss function when the model is less effective on new data. Both methods help in improving the machine learning model through various approaches.
- L1 Regularization (Lasso): This adds a penalty that is equal to the sum of the absolute values of the model’s coefficients. What makes L1 regularization stand out is its ability to make some of the coefficients exactly zero. This means the model can automatically pick the most important features and ignore the rest, which is really helpful when dealing with large datasets that have many variables. L1 regularization simplifies the model by focusing on less important features.
Mathematically, it looks like this:
Loss = Original Loss + λ * Σ|wi|
- L2 Regularization (Ridge): On the other hand, L2 regularization adds a penalty that’s the sum of the squared values of the coefficients. Unlike L1, this method doesn’t set any coefficient to zero. Instead, it makes all the coefficients smaller, pulling them closer to zero but not eliminating them. This makes the model more stable, especially when dealing with data that has a lot of interrelated features. However, it doesn’t help with selecting features like L1 does.
Mathematically, it’s represented as:
Loss = Original Loss + λ * Σ(wi^2)
21. How does a support vector machine (SVM) work?
A Support Vector Machine works by looking at data and trying to find the best line or boundary that separates it into different groups. It places the line in a way that maximizes the distance between the groups, making the separation as clear as possible. This helps the computer easily decide which group new data belongs to.
SVM examines the data points and tries to find a line that divides them into separate classes. This line should have as much space as possible between the closest points from each class, which are known as “support vectors.” The larger the gap between these classes, the more likely the model will perform well when given new data.
SVM works with both simple linear and complex non-linear problems. When it comes to more complicated cases, SVM uses special functions called kernels. These kernels move the data into another space, where it becomes easier to draw the dividing line. By following this method, SVM can tackle many classification problems effectively.
22. What is the k-nearest neighbor (k-NN) algorithm?
The k-nearest neighbor (k-NN) algorithm that’s often used in sorting data into groups{classes} or predicting outcomes. In this when a new piece of data inputs then the algorithm checks the relatable data points it already knows. It finds the nearest ones and decides what group the new data belongs to based on what’s common among its closest neighbors. The number of neighbors it looks at, called “k,” is something you decide. If most of the nearby data belongs to one group, the new piece is put in that group. This method is pretty simple and great for smaller sets of data, but it can become slow when dealing with larger amounts of information.
Here’s how it works:
First, it calculates the distance between a new data point and all the points in the training dataset, using methods like Euclidean or Manhattan distance.
Then, it picks the closest k data points, which are considered its “neighbors.”
For classification tasks, the algorithm looks at the most common category among these neighbors and assigns that category to the new data point.
In regression tasks, it takes the average of the values of the neighbors. Choosing the right k is important—if k is too small, the model might become too sensitive to outliers, while if k is too large, it might overlook key details in the data.
23. What is the purpose of dimensionality reduction, and what methods can be used?
Dimensionality reduction simplifies complexities of process of machine learning reducing input variables while retaining important data features. technique creates simpler models, cuts down on computational costs, & helps tackle the “curse of dimensionality.” The curse lead to overfit, which makes models less effective with complicated data.
Common Methods for Dimensionality Reduction
- Principal Component Analysis (PCA): PCA is a well-known way to reduce dimensions. It changes data into a new coordinate system. In this system, the first coordinate (or principal component) represents the direction with the most variation. The second coordinate captures the next largest direction of variation, and the process continues. By concentrating on these top components, PCA keeps the majority of the data’s variability while lowering dimensions.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): This specifically converts high-dimensional data into two or dimensions to facilitate visualization. It examines connections among data points strives to maintain these relationships while reducing dimensions. Applying t-SNE can reveal patterns or clusters within the dataset.
- Linear Discriminant Analysis (LDA): Linear Discriminant Analysis is a technique that helps to clearly separate different classes in the data. It’s useful when you want to reduce dimensions but still keep classes distinct.
- Autoencoders: Autoencoder is one of the type of neural network. Which is used for unsupervised learning. It is further divided into two parts: encoder and decoder. The encoder compresses data into a small form. And the decoder reconstructs the original data from this condensed version. They’re good at finding the difficult patterns within the data.
24. Explain how the Naive Bayes classifier works.
The Naive Bayes classifier is a group of probabilistic methods. That is used for categorizing items based on their probabilities. It is known as “naive” due to its basic assumption that the features (or traits) employed in the classification are independent from one another, a notion that frequently does not hold true in real-world situations.
How It Works
1. Bayes’ Theorem: This formula helps the classifier find the probability of each category based on the given features:
P(C∣X) = (P(X∣C)⋅P(C)) / P(X)
- P(C∣X) is the probability of category C given features X.
- P(X∣C) is the likelihood of the features given the category.
- P(C) is the initial probability of the category.
- P(X) is the probability of the features.
- Independence Assumption: To make calculations easier, it assumes each feature is independent from others within the same category. So, the probability of features is calculated by multiplying their individual probabilities.
- Prediction: For a new set of features, the classifier calculates the probabilities for each category and picks the one with the highest probability.
25. What is a neural network? Describe its components.
Neural network is a of computer model that takes inspiration from human brain. Its main goal? To recognize patterns in data and make predictions based on what it learns. The network has layers of connected nodes, also as neurons. Each neuron simple calculations and sends its results to the next layer.
Components of a Neural Network
- Input Layer: This is the first layer in a neural network. Every neuron in this layer represents a feature from the data set, helping the system process the initial information.
- Hidden Layers: This layer is present between the input and output layer. This transforms the data between them. They take the information from the input layer and transform it. Each neuron here evaluates the intensity of its inputs, then applies an activation function like ReLU or sigmoid allowing the network to handle more complex data.
- Output Layer: This is the last layer. It gives us the final output using a softmax activation function, which calculates probabilities for each category.
- Weights and Biases: The neurons in a network are connected by weights, which adjust during the learning process. Biases are added to these connections to help fine-tune the model, making sure it can better fit the data.
26. What is ensemble learning? How do bagging and boosting work?
Ensemble learning is a method in machine learning that helps improve the overall accuracy by combining different models. The idea is that while one model might not be very strong on its own, when several weaker models work together, they can make much better predictions. Two common ways to use ensemble learning are bagging and boosting.
- Bagging (Bootstrap Aggregating): Bagging works by creating many copies of the same model and training each one on a different set of data. These data sets are made by randomly picking samples from the original data, sometimes repeating the same samples. After training, all the models come together, and their results are combined. For example, in regression problems, they average the predictions, while in classification problems, they vote on the final result.
Example: A well-known example is Random Forest. It combines many decision trees to make predictions more accurate and reduce the risk of making mistakes. - Boosting: Boosting takes a different approach. Instead of training all the models at once, it builds them one after another. Each new model learns from the mistakes the previous models made. After training, the results are combined, but models that made more accurate predictions are given more importance.
Example: Algorithms like AdaBoost and Gradient Boosting are popular methods of boosting. They focus on the hard-to-predict data points, giving more attention to improving accuracy on those tough cases.
27. How do you handle imbalanced datasets? What techniques can be applied?
The condition of imbalance datasets occurs when the classification of classes does not happen equally, leading to the bias outcomes in machine learning models. For instance, in the fraud detection scenario, handling imbalanced datasets that may represent only a small fraction of total transactions is crucial to ensure that models work well across all classes.
Techniques for Handling Imbalance
- Resampling Methods:
- Oversampling: This approach increases the number of samples in the smaller category. You can either repeat existing data or generate new, similar examples using techniques like SMOTE (Synthetic Minority Over-sampling Technique).
- Undersampling: This strategy reduces the number of samples in the larger category to even things out. However, it might lead to losing important information, so it should be used carefully.
- Cost-Sensitive Learning: Another option is to assign more weight to mistakes made on the smaller group. By adjusting the model to make errors on the minority class more costly, the model will pay extra attention to making better predictions for that group.
- Ensemble Methods: Techniques such as balanced random forests and boosting can help as well. These methods focus more on the smaller group during the learning process, improving performance across the board.
- Anomaly Detection: In cases where the minority group is extremely rare, like fraud detection, you can treat it as an anomaly. Instead of classifying everything, the model is trained to recognize unusual patterns, helping identify rare events with greater accuracy.
28. Explain how transfer learning works.
Transfer learning is a smart technique of machine learning. It takes what the machine has already learned from one task. Then uses that knowledge to do better on a new but related task. This method is especially useful when you don’t have a lot of labeled data or when getting that data is too costly.
How Transfer Learning Works
Transfer learning operates on a model that already trained on a big set of data.. Then, it fine-tuned model to make it work for a different task. Here’s how it usually happens:
- Pre-training: First, the machine gets trained on a large dataset. This step helps the model learn basic patterns and features. Popular models like VGG, ResNet, or BERT are trained this way, learning from huge amounts of data.
- Fine-tuning: Once the model has learned general things, it’s adjusted for the new task. This is done by using a smaller dataset that’s specific to the new task. Some parts of the model may be kept the same to hold onto what it’s already learned. Other parts are retrained to focus on the new job.
- Evaluation: Finally, the model is tested on the new task. That help to see how well it performs. If it does a good job, the process works.
Also Read: Star Interview Method: Complete Guide, Questions and Answers
29. What are generative adversarial networks (GANs)?
Generative Adversarial Networks (GANs) are a type of machine learning system used to create new data that looks like real data. They work by having two different networks, the generator and the discriminator, compete with each other.
Components of GANs
- Generator: The generator network takes random noise as input and generates synthetic data samples. Its objective is to produce data that is indistinguishable from real data.
- Discriminator: The discriminator network evaluates data samples, distinguishing between real samples from the training dataset and fake samples generated by the generator. Its goal is to correctly classify samples as real or fake.
Wrapping Up
Machine learning lets computers learn, memorize, and produce accurate outputs. It has helped businesses to make wise judgments essential for simplifying their operations. From manufacturing, retail, healthcare, energy, and financial services, these data-driven decisions enable businesses across sector verticals to maximize their present operations and find new ways to reduce their general workload.
Read More: What Is Interview As A Service, And How Is It Different From Traditional Hiring Method
Ready to Transform Your Hiring Process?
Discover how our AI-powered interview platform can streamline your recruitment and find the best candidates faster.

Related Blogs

Why Universities Are Turning to AI for Assessment Integrity?
Universities are turning to AI surveillance to secure assessments, prevent malpractice, and ensure fair evaluation of student skills.

Exit Interviews: The New Pathway to Employee Retention
In the current business scenario, employee retention is a bigger problem than ever. Businesses are concerned about employees leaving the organization and want to work...

How Crowdsourcing Improves the Hiring Process?
When it comes to hiring, finding talent isn’t an exercise in patience, it’s about knowing where to search. Job boards are like taking a shot...

Mock Interview for Freshers: Get Ready to Land Your Dream Job
Freshers can now prepare for job interviews with AI-powered mock sessions. Practice real questions, get feedback, and build confidence to land your first job.

How Interview Scheduling Platforms Can Save Recruiters Hours
Scheduling an interview seems very easy. All you have to do is call the candidate, fix the time, and voila! You are done. But unfortunately,...

10 Best Video Interview Tools for Your Business
Over the years, employers have been using video interview tools. But, the COVID-19 pandemic pushed businesses to adapt, leading to a surge in the use...


